psychology
Zero-Shot Foundation Models
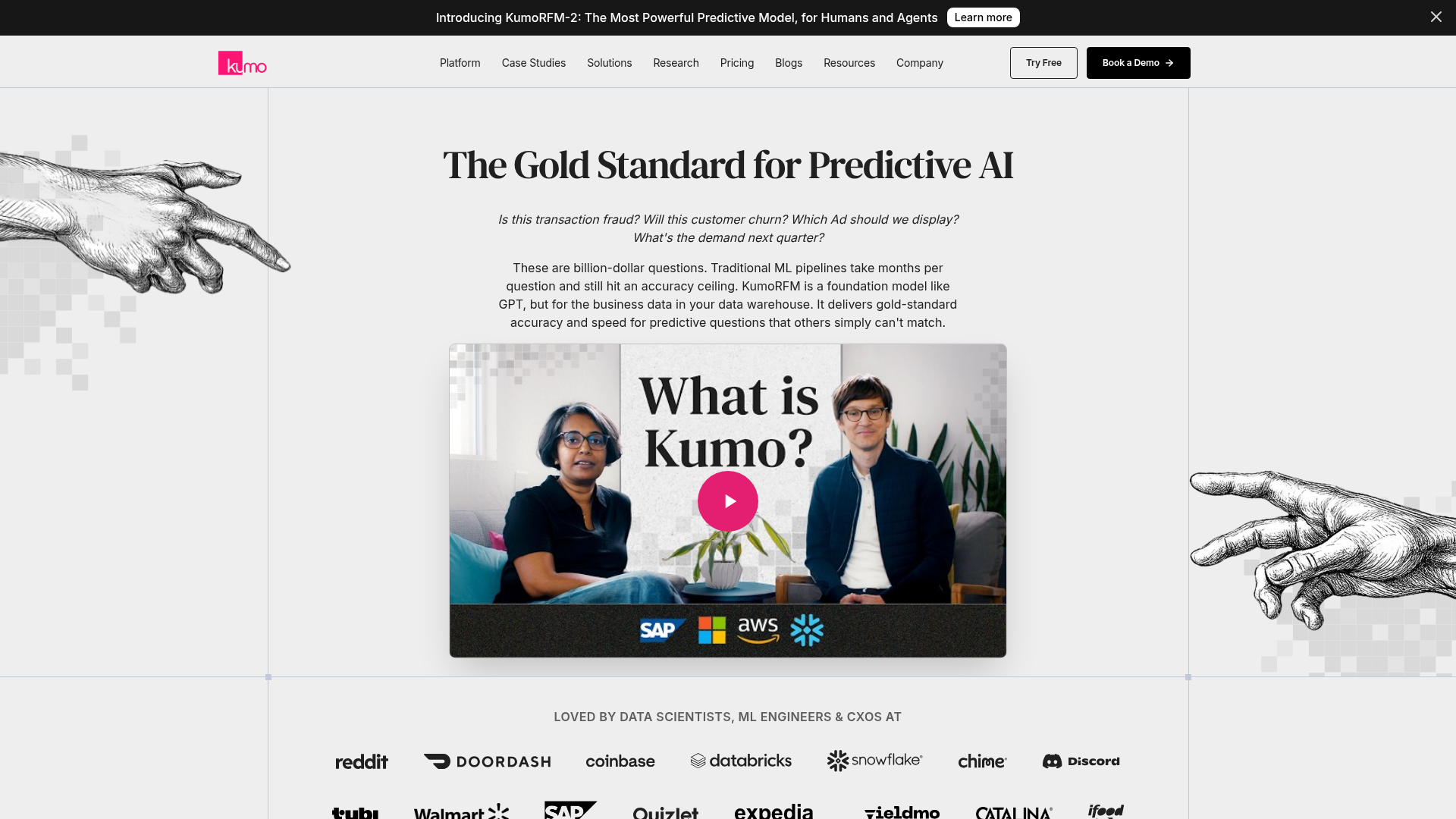
KumoRFM is a foundation model pre-trained on relational data patterns. Point it at your schema and get predictions without any training data labeling or model building. This is the core differentiator: useful predictions from day one, not day ninety.
bolt
Real-Time Predictions
Predictions are generated in seconds, not hours. This makes it viable for operational workflows where you need fresh scores on demand rather than waiting for a nightly batch job to complete.
storage
Native Data Warehouse Integration
Connects directly to your existing warehouse. No data extraction, no CSV uploads, no separate data pipeline to maintain. Your data stays where it is, and Kumo reads the relational structure natively.
tune
Fine-Tuning at Scale
When zero-shot is not enough, you can fine-tune the model on your specific data to improve accuracy. This bridges the gap between "quick and good enough" and "production-grade precision" for high-stakes use cases.
security
Enterprise-Grade Security
SOC 2 compliance and enterprise security controls. Data stays within your warehouse environment. This matters for regulated industries like finance and healthcare where data residency is non-negotiable.
visibility
Transparent Explainability
Predictions come with explanations of which features drove the result. This is critical for stakeholder buy-in. Nobody wants to act on a black-box score; they want to understand why a customer is flagged as high-churn.