What makes the AI nodes release worth paying attention to.
account_tree
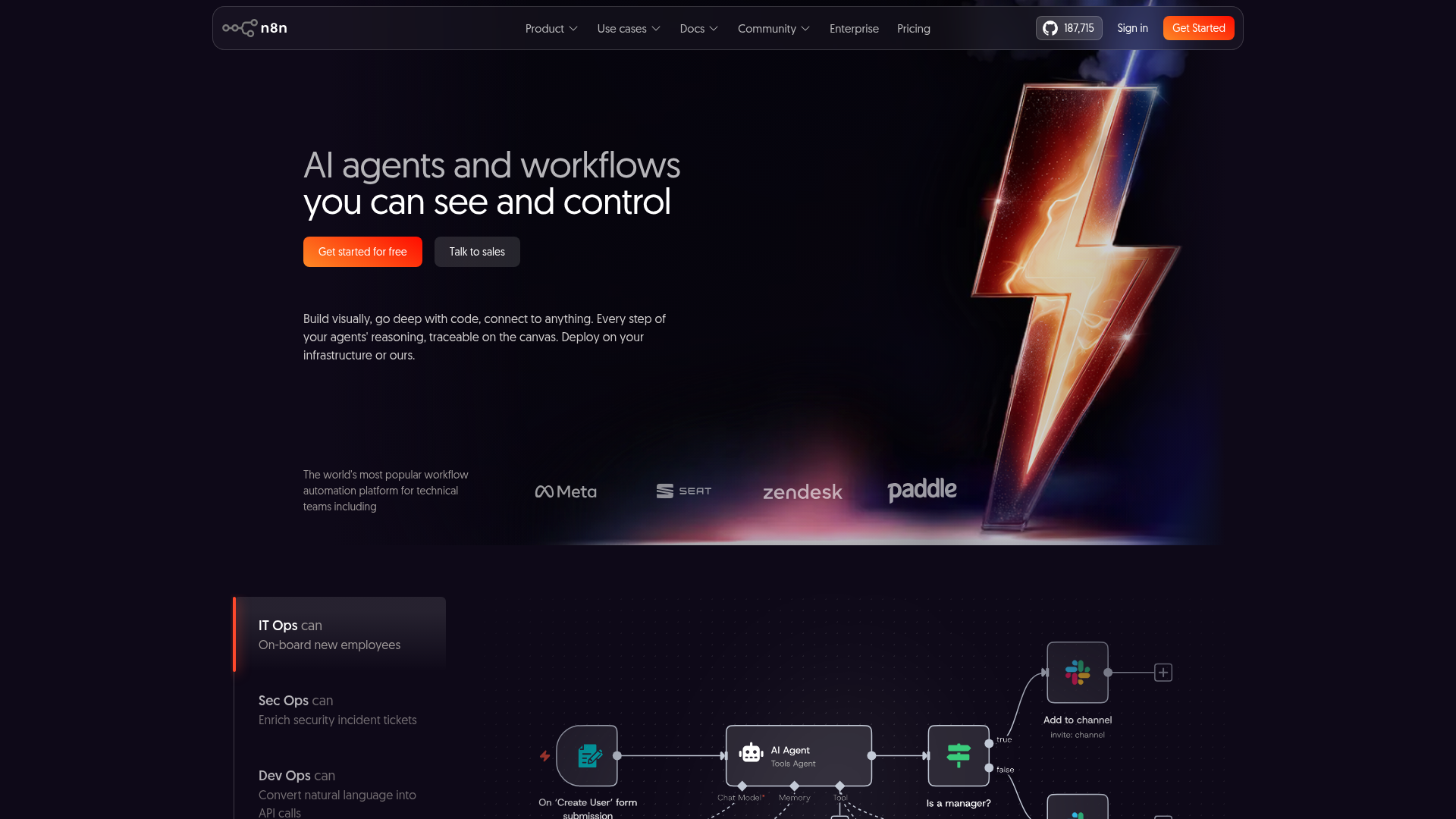
Visual Workflow Builder with AI Steps
Drag and drop LLM calls alongside HTTP requests, database queries, and script nodes. Each AI node is a discrete, testable step. No black-box abstractions.
smart_toy
Multi-Model Support
GPT-4o, Claude 3.5, Llama 3, Mistral, and any OpenAI-compatible endpoint. Swap models per node. Run cheap models for triage and expensive ones for final output.
replay
Re-run Single Steps
Failed LLM call? Re-run just that node with real data from the previous execution. No need to replay the entire pipeline. This alone saves hours of debugging time.
security
Self-Hostable, Open Source
Deploy on your own Docker or Kubernetes cluster. API keys, prompts, and data never leave your network. Critical for teams handling PII or operating under SOC 2 constraints.
error_outline
LLM-Powered Error Handling
Build retry branches that feed error logs into an LLM node for diagnosis before deciding whether to retry, escalate, or reroute. Intelligent failure recovery, not just exponential backoff.
code
Code and No-Code Hybrid
Chain Python or JavaScript function nodes with AI nodes in the same workflow. Parse LLM output with custom scripts, run embedding lookups, or transform data between steps.
hub
400+ Integrations
GitHub, Salesforce, ServiceNow, Asana, Slack, Docker, and hundreds more. AI nodes slot into existing integration workflows without rebuilding anything.
receipt_long
Audit Logs and Log Streaming
Every execution, every LLM call, every input/output pair is logged. Stream to your SIEM or observability stack. Essential for debugging prompt drift in production.